深入了解消息队列:大型分布式系统中的必需基础设施?
<配资注册>深入了解消息队列:大型分布式系统中的必需基础设施?
1. 引言
普通小型业务一般用不到消息队列,但在一些大型分布式系统中,消息队列是必需项,本文旨在对消息队列构建一些基本认识。
在小型系统里,常用 同步调用:比如服务 A 想要下单,就直接调用服务 B(库存)、C(支付)、D(物流)。一切都很直观。可当系统变大、用户量激增时数据埋点需求怎么写,问题会越来越明显:
这就是为什么需要 消息队列( Queue,简称 MQ)。
它的作用,就像一个 “缓冲层”:
因此,在现代分布式架构中,消息队列已经成为和数据库、缓存一样的 基础设施。
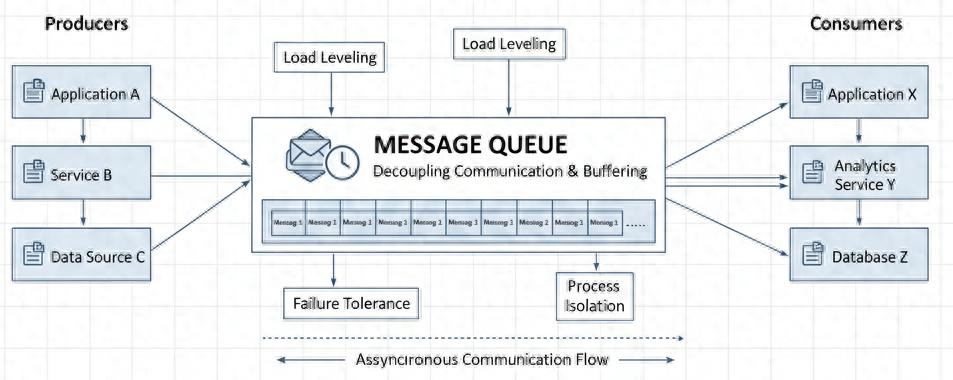
消息队列结构图(made by nano )
2. 什么是消息队列2.1 基本概念
消息队列就是 存放消息的队列。不过这里的“队列”不是单机内存里的数据结构,而是一个独立的中间件服务,具备以下特点:
常见角色:
消息()一段需要传递的数据,比如订单 ID、日志内容、用户行为事件等。 消息往往包含 消息体() + 消息头(/),前者是业务数据,后者是路由、时间戳、优先级等控制信息。生产者()负责把消息写入队列的服务。比如电商里的“订单系统”。消费者()负责从队列中取消息并处理的服务。比如“短信通知服务”。 消费者可以是一个,也可以是一组(消费集群),用来分担处理压力。(消息代理)消息的“中转站”,通常由专门的 MQ 服务实现,比如 、Kafka。 它负责存储消息、分发消息、保证可靠性。
简单来说,消息传递的流程是:
生产者 → (消息队列) → 消费者
这相当于在系统之间加了一层“缓冲”,把发送和处理解耦。
2.2 两种核心通信模型
消息队列主要有两种通信模式,不同业务场景下选择也不同:
点对点模型(Queue)一条消息只能被一个消费者消费。适合任务分发,比如“打印任务队列”:用户提交 10 个打印任务,后台有多个打印机进程,每个任务只会被其中一个打印机处理。发布/订阅模型(Topic)一条消息可以被多个消费者订阅。适合事件通知,比如“用户注册事件”:注册成功后,积分系统、推荐系统、邮件系统都需要各自处理同一个事件。
这两种模式可以看作 “单播” 和 “广播” 的区别。
2.3 与传统调用的区别异步调用(消息队列)3. 消息队列的核心特性
消息队列之所以能成为现代分布式系统的“基础设施”,就在于它提供了一组通用而强大的特性。这些特性让开发者在应对高并发、分布式解耦、异步通信时,可以少操心很多“底层细节”,把精力集中在业务逻辑本身。
3.1 解耦:让系统像“积木”一样组合
在没有消息队列之前,服务之间的调用往往是强耦合的:
结果就是,系统间关系越来越复杂,像“蜘蛛网”一样。
消息队列的引入,提供了发布-订阅模型:
这样深入了解消息队列:大型分布式系统中的必需基础设施?,A 与下游服务的关系就从“紧耦合”变成了“松耦合”。在微服务架构里,解耦是第一需求,也是消息队列的最大价值之一。
3.2 异步:把“长事务”拆解成小片段
现实世界中,很多操作并不需要实时同步完成。
举个例子:
而通过消息队列:
这样用户体验更好,系统整体吞吐量也更高。
3.3 削峰填谷:应对突发流量的“蓄水池”
电商系统里有个著名场景:秒杀。
消息队列在这里就像一个“蓄水池”:
这样,系统的整体吞吐能力没有提高深入了解消息队列:大型分布式系统中的必需基础设施?,但却能避免瞬间被压垮。 这就是所谓的“削峰填谷”:把流量高峰削平,让系统处理得更平稳。
3.4 可靠性:消息不能“凭空消失”
消息队列的一个基本承诺是:消息不会凭空消失。
这听起来简单,但其实很难。要保证消息可靠性,往往涉及:
不同 MQ 系统在可靠性上的保证不一样:
3.5 顺序性:消息要不要按顺序处理?
有些场景对顺序极其敏感:
消息队列在默认情况下,可能会因为分区(Kafka)或多消费者并行(),打乱顺序。
解决办法通常有两种:
单分区顺序保证:把同一用户、同一订单的消息写入同一个分区或队列。幂等性设计:让下游消费者不依赖严格顺序,而是能够根据“状态机”处理(比如订单只有在“已支付”状态下才能进入“已发货”)。3.6 可扩展性:从单机到分布式集群
随着业务发展,消息量会越来越大。 一个单机 MQ 最多撑到百万级 TPS,再往上就需要水平扩展。
4. 常见消息队列产品对比
在业界,消息队列的产品选择很多,不同的 MQ 背后都有各自的设计哲学和擅长场景。 我们可以把它们大致分为两类:
4.1 —— 功能最丰富的“瑞士军刀”
背景
最早诞生于 2007 年,基于 开发,遵循 AMQP(高级消息队列协议)。它的设计目标就是企业级应用的消息传递标准化。
特点
适用场景
不足
就像是一把 瑞士军刀,功能全,适合处理“事务性”业务,但如果你要应对“双 11 秒杀”这种亿级流量,它就显得吃力。
4.2 —— 老牌选手,逐渐边缘化
背景
出自 基金会,比 还早(2004 年),是很多老系统的默认 MQ。
特点
适用场景
不足
4.3 Kafka —— 高吞吐的“日志流处理引擎”
背景
Kafka 由 于 2011 年开源,现在已经成为 旗下最活跃的项目之一。它的定位与传统 MQ 不一样:本质上是一个 分布式日志流系统。
特点
适用场景
不足
4.4 —— 阿里出品的“双 11 战神”
背景
最初由阿里巴巴开发,用来支撑“双 11”亿级流量,后来贡献给 。它融合了传统 MQ 的事务特性和 Kafka 的高吞吐能力。
特点
适用场景
不足
可以看作 融合型选手:既有 的事务保证,又有 Kafka 的高吞吐,非常适合互联网业务。
一句话总结:
5. 消息队列在实际工程中的典型应用场景
消息队列并不是“为了用而用”,而是为了解决系统中的一些 经典痛点:服务耦合过紧、请求处理过慢、流量波动剧烈、数据处理不及时…… 在实际工程中,MQ 的身影无处不在。下面我们从几个典型的应用场景来看它的价值。
5.1 服务解耦 —— 系统间的“缓冲带”
问题场景假设你在开发一个电商网站。用户下单后,需要:
生成订单(订单服务);扣减库存(库存服务);发短信通知(短信服务);推送积分(积分服务)。
如果这些逻辑都写在“下单接口”里,调用链会很长:
消息队列方案
这样做的好处:
真实案例
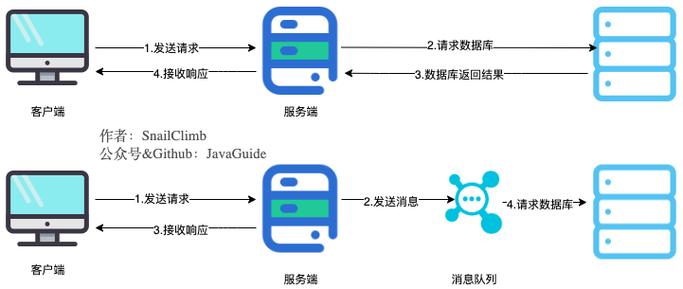
淘宝的下单链路就是这种模式:用户下单触发 MQ 事件,库存、支付、物流等各系统异步接收处理。
5.2 流量削峰 —— 秒杀场景下的“安全阀”
问题场景
“双 11”秒杀开始的 1 秒钟内,可能有几百万用户同时点击“立即购买”。 如果请求直接打到数据库,数据库连接数会瞬间被占满数据埋点需求怎么写,系统崩溃。
消息队列方案
直观比喻
消息队列就像是水库:洪水来了,先蓄起来,再慢慢放水。
真实案例
京东、拼多多在秒杀活动中都会用 MQ 来做“流量削峰”。甚至还会在 MQ 前再加一层 Redis 缓存,进一步拦截无效请求。
5.3 异步处理 —— 提升用户体验
问题场景
用户注册后,需要发送欢迎邮件。如果这个动作在注册接口里同步执行,用户可能要多等 2 秒。
消息队列方案
好处
延伸案例
微信的红包功能:用户点“发送红包”时,消息会异步入队,后端慢慢推送,保证体验丝滑。
5.4 日志收集 —— 让数据流动起来
问题场景
在分布式系统里,每个服务都会产生日志:访问日志、错误日志、埋点数据…… 如果直接把日志写到数据库或 HDFS,写入压力巨大,而且难以统一处理。
消息队列方案(Kafka 典型)
真实案例
5.5 事务保证 —— 电商与金融的必备
问题场景
在金融交易或电商支付中,必须保证操作的 一致性。比如:
消息队列方案
、Kafka(带事务扩展)都支持 事务消息:
这样可以确保本地事务和消息发送的一致性。
真实案例
支付宝在支付链路中大量使用事务消息,确保扣款与订单更新的一致性。
5.6 广播与通知 —— 一次发布,多方订阅
问题场景
假设一个新闻网站需要推送热点新闻:
如果用传统调用,发布服务要写三次逻辑。
消息队列方案(发布-订阅模型)
好处
真实案例
微信公众号推送就是类似模式:一次发布,N 个订阅者同时收到。
5.7 小结
消息队列的价值,体现在对现实问题的解决能力上:
6.使用消息队列时的挑战与最佳实践
消息队列虽好,但用起来并非一劳永逸。
在实际生产环境中,开发者往往要面对 消息积压、顺序保证、重复消费、消息丢失 等棘手问题。
这些问题如果没有处理好,轻则业务延迟,重则直接导致数据错乱、订单出错。
6.1 消息积压问题
现象
在促销、秒杀等高并发场景下,生产者发送消息的速度远超消费者的处理速度,导致队列中的消息越堆越多,甚至撑爆存储。
危害
常见应对方案
增加消费者数量:水平扩展消费者实例,提高消费并发度。限流削峰:在生产端做限流 + 消息缓冲,避免流量瞬间冲击 MQ。例如秒杀系统,先写入 Redis 队列,按速率再投递到 MQ。分区消费(Kafka、):将消息分到多个分区,让多个消费者并行处理。优先级消息:将重要消息优先处理,次要消息延迟处理。6.2 消息顺序问题
现象有些业务要求消息严格有序,比如“下单 → 扣库存 → 支付”。但在分区或多消费者场景下,消息可能乱序。
危害
常见应对方案
单分区顺序消费Kafka/ 支持设置某类消息只进入同一分区,从而保证顺序。代价:吞吐量受限,容易成为瓶颈。业务层幂等控制即使顺序乱了,也能通过幂等逻辑保证最终一致性。例如订单状态只允许单向流转(未支付 → 已支付 → 已发货),不允许逆转。6.3 消息重复消费
现象
在“至少一次”投递语义下,可能出现同一条消息被多次消费的情况。例如消费者在处理消息后还没来得及提交确认,MQ 认为它失败了,就会重试投递。
危害
常见应对方案
幂等性设计给消息加唯一 ID,在数据库操作前检查是否已处理过。使用分布式锁或去重表来确保只处理一次。让消费者具备“处理多次等于一次”的能力。常见做法:精确一次语义( Once)Kafka 通过事务 + 幂等生产者支持“准”精确一次,但代价是复杂度和性能损耗。6.4 消息丢失问题
现象
消息可能在生产端、MQ 本身、消费端三个环节丢失。 例如生产者发送消息后没等确认就退出;MQ 崩溃丢了未持久化的消息;消费者没处理完消息就挂掉。
危害
常见应对方案
生产端确认机制生产者必须开启“消息发送确认”,确保消息真正写入队列。MQ 持久化配置启用磁盘写入(Kafka、 默认有 WAL 日志)。 需要手动设置消息持久化。消费者确认机制消费者只有在成功处理消息后,才确认 ACK。避免“先确认再处理”的错误模式。监控告警建立投递链路的端到端监控,确保消息数一致。6.5 延迟消息与定时任务
一些业务场景需要“延迟投递”,比如:
很多 MQ 原生不支持延迟消息(Kafka 就不支持),需要额外实现。
常见实现方式
死信队列(DLQ)+ 、 提供 TTL(存活时间)和死信队列,可以模拟延迟投递。调度任务系统结合定时任务(、xxl-job)+ MQ,完成延时处理。 的延时等级机制 支持多级延迟时间配置,但不够灵活。7. 未来趋势与总结7.1 消息队列在架构演进中的角色
从最早的 单体应用 到 微服务架构,再到如今的 云原生分布式系统,消息队列的角色一直在发生变化。
一句话总结:消息队列从“辅助组件”,成长为“架构基石”。
7.2 与云原生的结合
云原生的目标是 弹性、自动化、跨平台。 传统 MQ 系统往往依赖运维团队手动搭建和维护,这与云原生理念相悖。
于是,出现了越来越多的 云端消息队列服务:
这些服务的特点是:
未来,消息队列逐步会走向 “消息即服务”( as a , MaaS) 的形态。
7.3 与 的融合
在 架构下,函数()是计算的最小单元,而消息队列恰好可以作为函数的天然触发器。
例如:
这类模式正在成为 事件驱动应用(Event- ) 的核心范式。 它意味着开发者不需要再手动写定时任务、轮询逻辑,只要 订阅事件 → 定义函数 即可。
7.4 总结
回顾全文,消息队列的价值主要体现在三点:
解耦 —— 让系统模块松耦合,便于扩展和演进。削峰填谷 —— 平滑应对突发流量,提升系统稳定性。异步处理 —— 提升性能,降低响应时间。
不同产品各有优势:
同时,工程实践中必须警惕 积压、乱序、重复、丢失 等问题,并通过 幂等性、限流、监控 等手段解决。
展望未来,随着 云原生、、EDA 的发展,消息队列将从“技术工具”升级为“业务中枢”,支撑更大规模、更智能化的分布式系统。
本文 配资注册 原创,转载保留链接!网址:http://wwww.yao-cn.com/html/1064.html
本文由[配资注册机构名称]原创撰写,著作权归[配资注册机构名称]所有。未经书面授权,任何单位或个人不得以任何形式复制、转载、摘编、修改、传播本文全部或部分内容。